I Want To Use Demos' Data To Measure Reactions
Reaction time is an important metric for understanding player behavior. Better players should have better reaction time, and unreasonable reactions indicate something is wrong with the game. I define reaction time as the number of ticks from when an enemy is visible until a player's crosshair is on the enemy. The problem with reaction time is that I need to know when each player is visible. I've been trying to use demos to compute visibility. These files enable us to replay matches from any players perspective. In theory, I should be able to compute visibility and reaction time from them. Unfortunately, I'm running into some problems with computing visibility from demo files.
Challenges Computing Visibility From Demos' Text Data
Demos store a text field called spottedBy. This field is supposed to indicate when a player is spotted by (becomes visible to) another player. However, it's so inaccurate that it's useless for computing visibility in reaction time. In the video to the right, the enemy's foot becomes visible on tick 1139. The demo's spottedBy field only indicates the enemy is visible on tick 1191. This 52 tick difference is almost an entire second on the 64 tick server. An error of roughly one second is unacceptable for computing visibility in reaction time, since reactions take 150-500ms.
Computing Visibility From Demos' Video Data
So we can't rely on demos' text fields to compute visibility. These fields are inaccurate because they rely on approximate definitions of visibility that are updated less frequently and less precisely than the character models that are drawn on screen when replaying a demo.
As shown in the above video, the video produced by replaying the demo videos has more accurate visibility data than the the text fields in the demo files like spottedBy. Therefore, an alternative approach for computing visibility is to replay the demo file and record when enemies were visible in the video.
I computed visibility from the video in two ways. First, I spent 16 hours analyzing roughly 30 minutes of footage by hand, stepping frame-by-frame through demo files and recording the first frame when an enemy became visible in an Excel file. This approach clearly won't scale, so I replaced it with an automated approach.
My second approach is a combination of the HLAE mod and a simple computer vision (CV) algorithm. I used the following HLAE script to make the replay videos easy to analyze for a computer vision algorithm. As shown in the video on the right, I made each of the five enemy a different color (red, yellow, green, blue, and pink), retained all the partially opaque effects (like smoke from gunshots), and made all the fully opaque effects black. Then, I ran a simple computer vision algorithm over the video: if (1) at least 5 pixels with an enemy's hue are visible (2) for at least 2 ticks (3) with saturation > 60/255 and value > 30/255 for HSV color values, record that as the player being visible. For each frame when a player becomes visible or is no longer visible, I ran OCR over the demo UI (the controls in the top left corner of the HLAE video) to extract the tick number. I need the restrictions on number of pixels, ticks of visibility, and HSV values in order to filter out noise from the smoke. I run the OCR only on ticks where players start or stop being visible since the OCR takes 95% of the time required to analyze each frame.
Demos' Video Data Is Also Inaccurate
I found multiple inaccuracies with the resulting visibility data. While my HLAE/CV approach was (largely) bug free, the videos produced from the demo files are still too inaccurate for computing reaction times. Moving from text fields like spottedBy to a video-based approach like HLAE/CV decreases the inaccuracy from a second to 150ms. This is a big improvement, but still too inaccurate to measure 150-300ms reaction times.
The first inaccuracy is that replaying a demo at different speeds produces different camera angles. The video on the right shows that the camera lurches forward when you pause the demo. The lurch causes enemies to become visible 5-10 ticks earlier when stepping frame-by-frame through a demo compared to playing the demo as a normal video. These 5-10 ticks result in 80-150ms faster reaction times when computing reaction time with hand-computed visibilities compared to my HLAE/CV-based visibilities.
The second inaccuracy is that different demo recording techniques have different errors in reproducing gameplay. There are two ways to record a demos. The first is called a POV (point-of-view) demo. This records all the gameplay visible to a single player from their computer. The second approach is called a GOTV demo, and it records the gameplay for all players from the server. The general consensus among the CSGO community seems to be that POV demos more accurately record a player's perspective. The POV demos record the gameplay of a behavior on their computer, while the GOTV ones only record the subset of player behavior sent to the server.
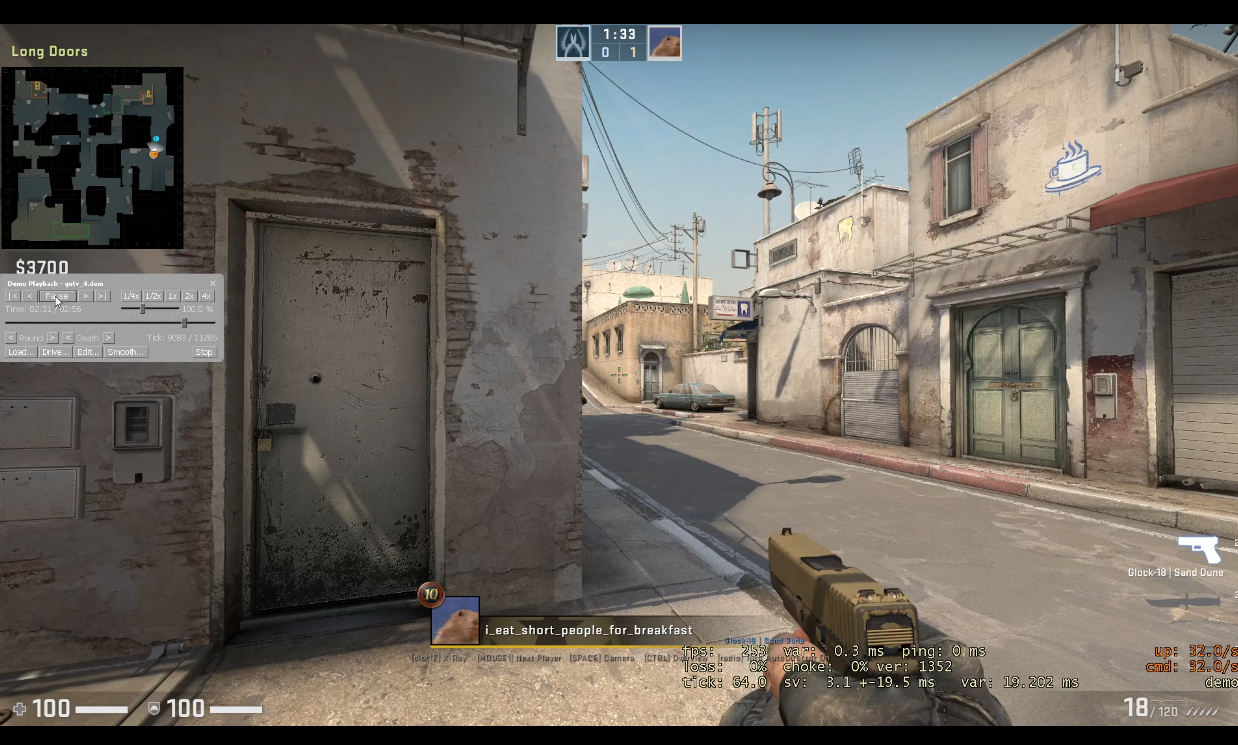
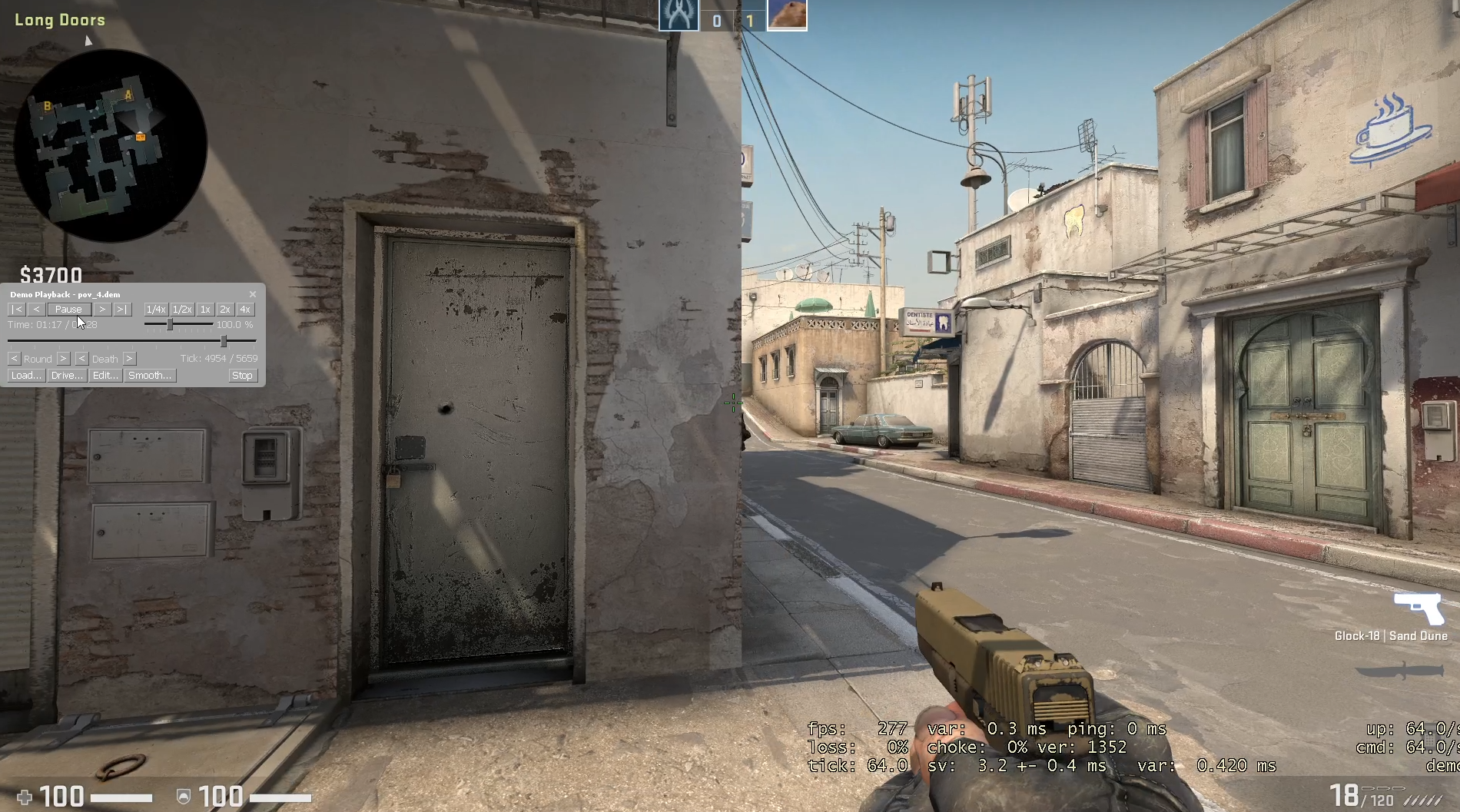
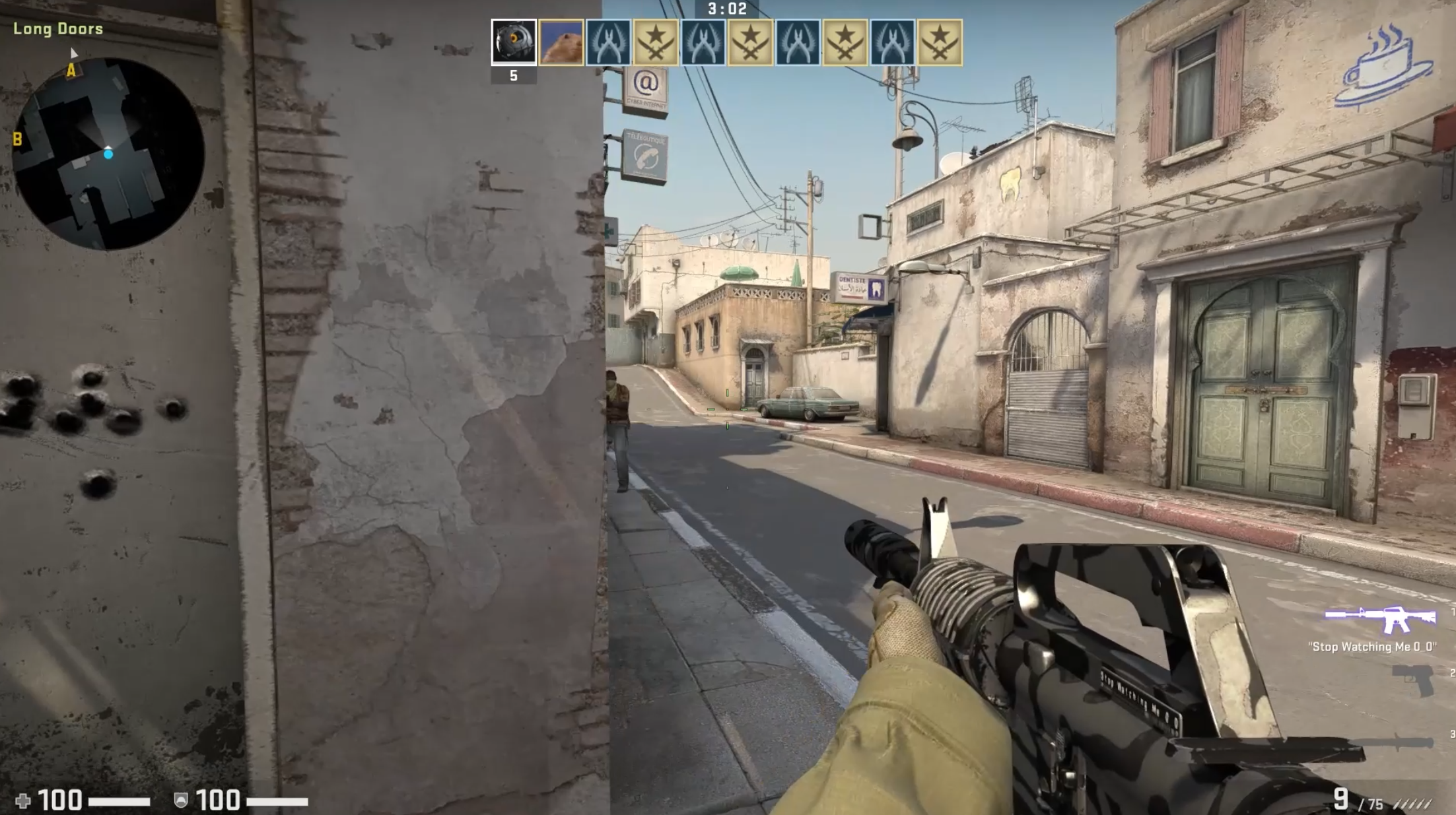
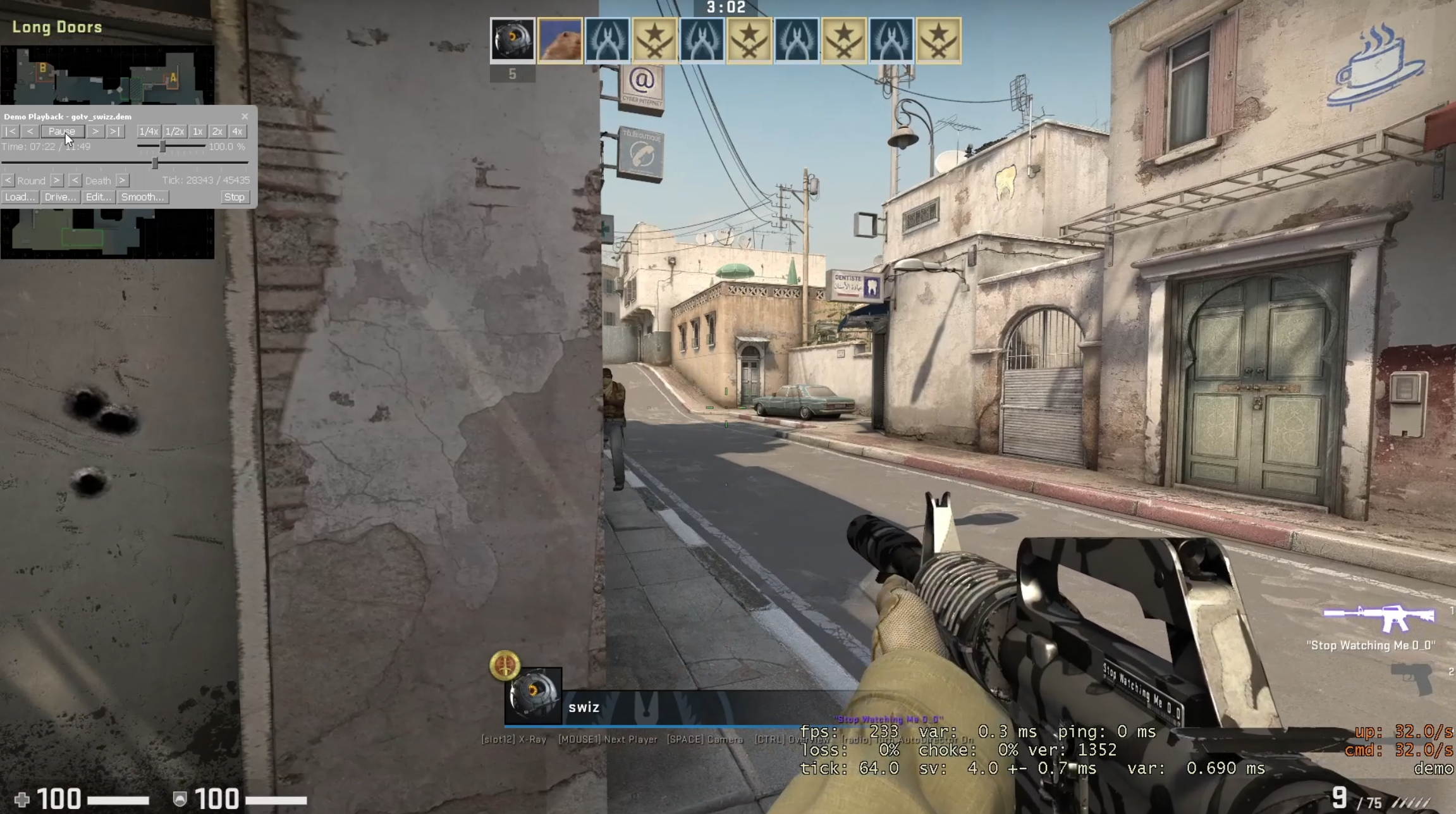
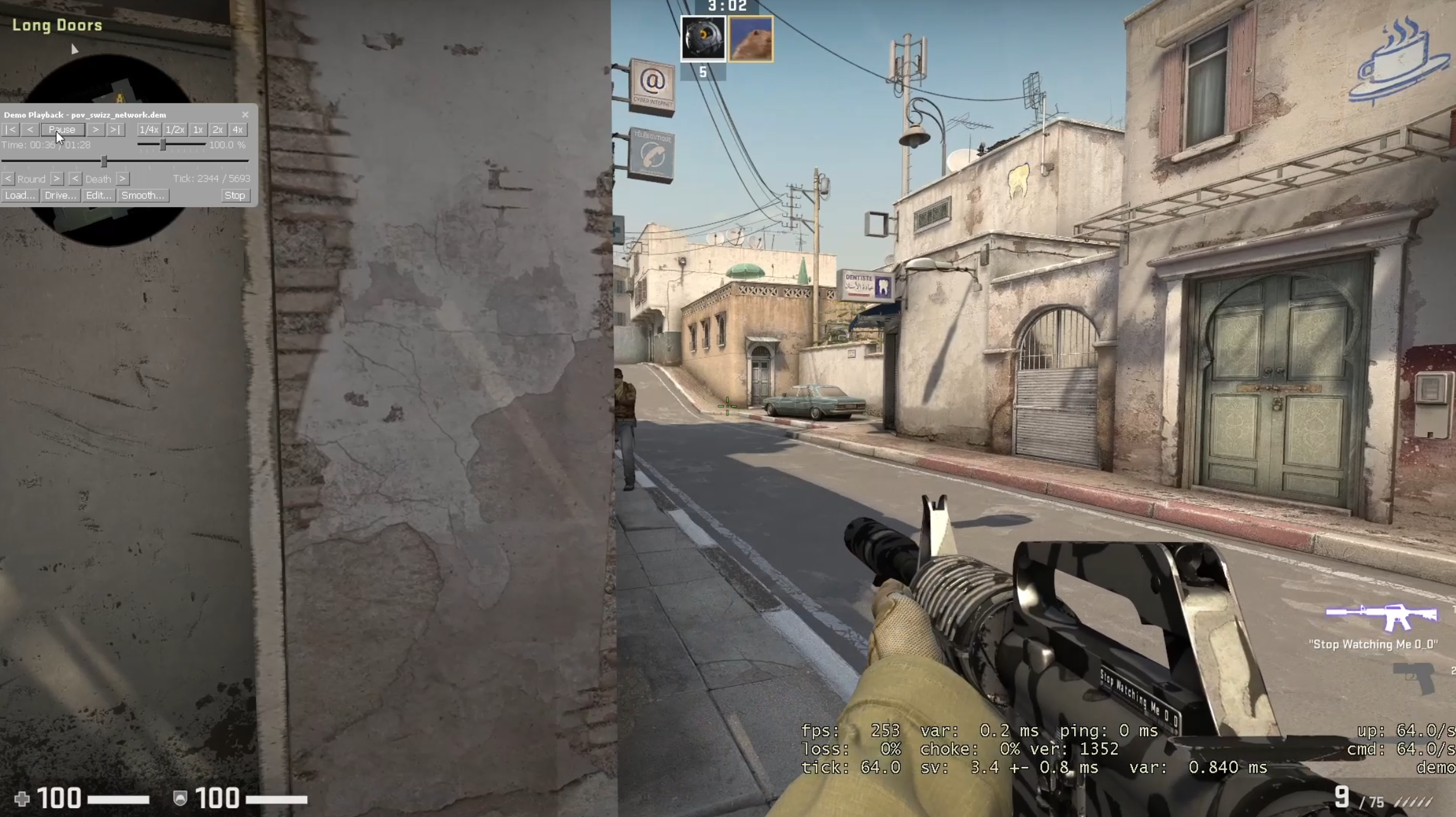
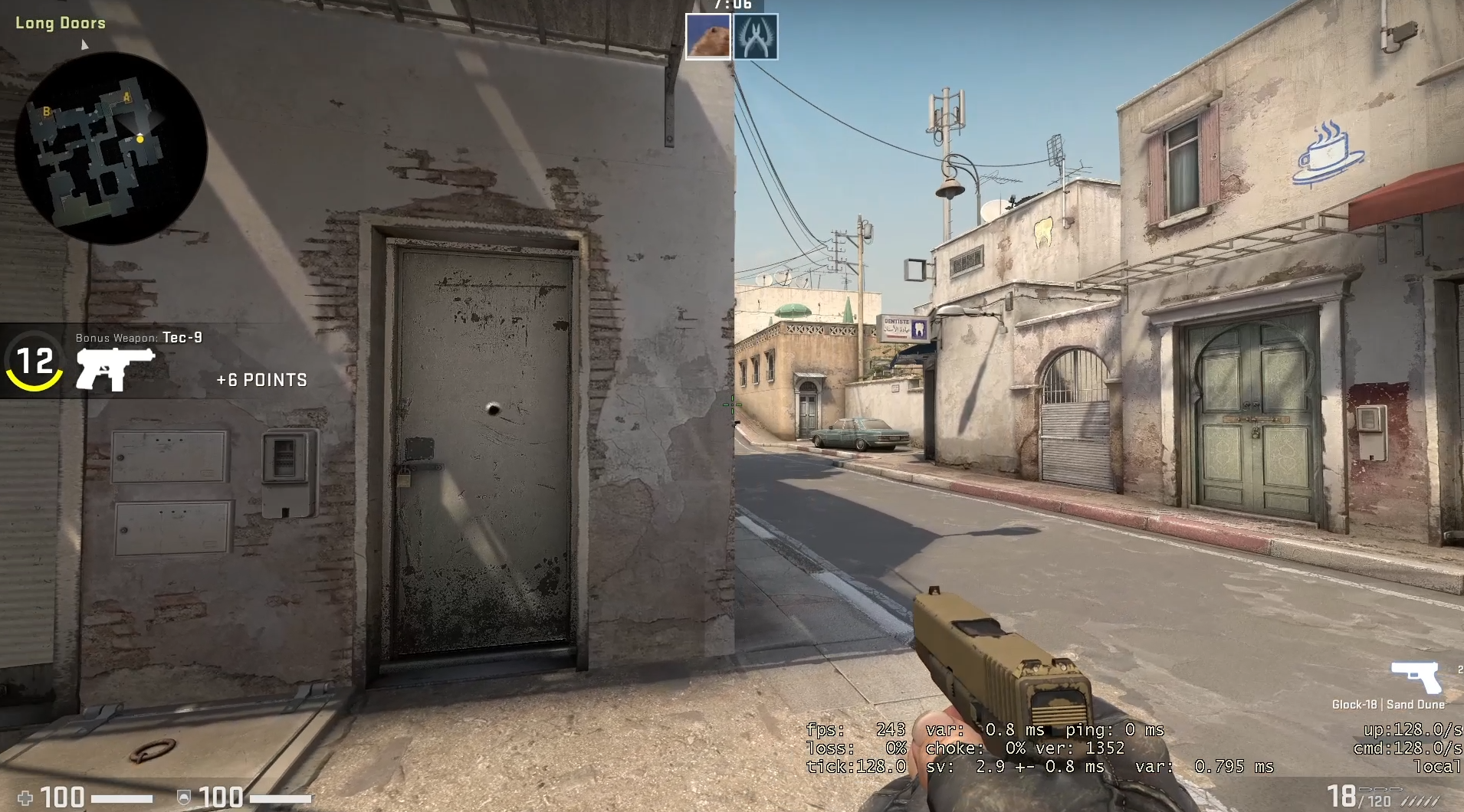
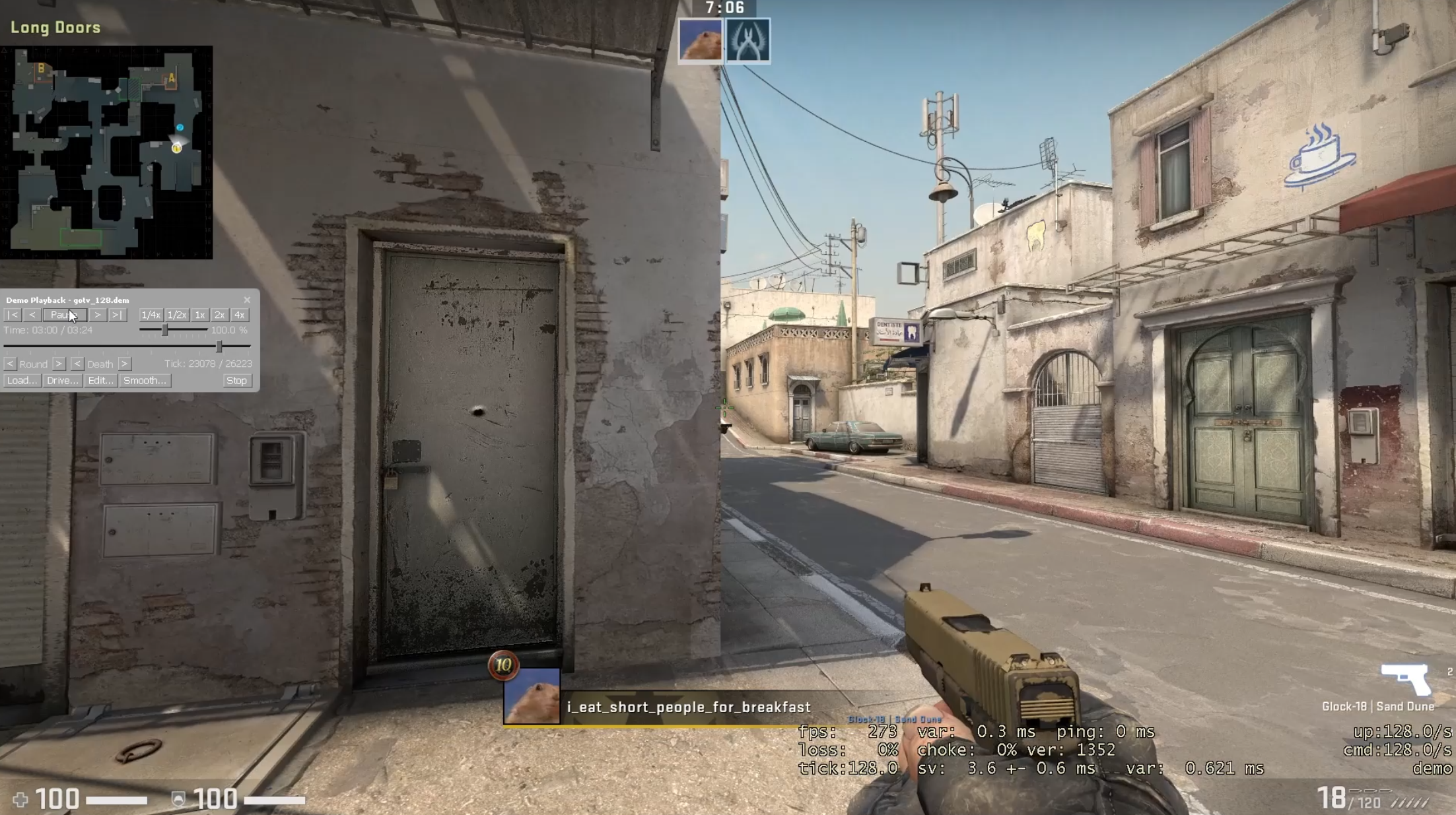
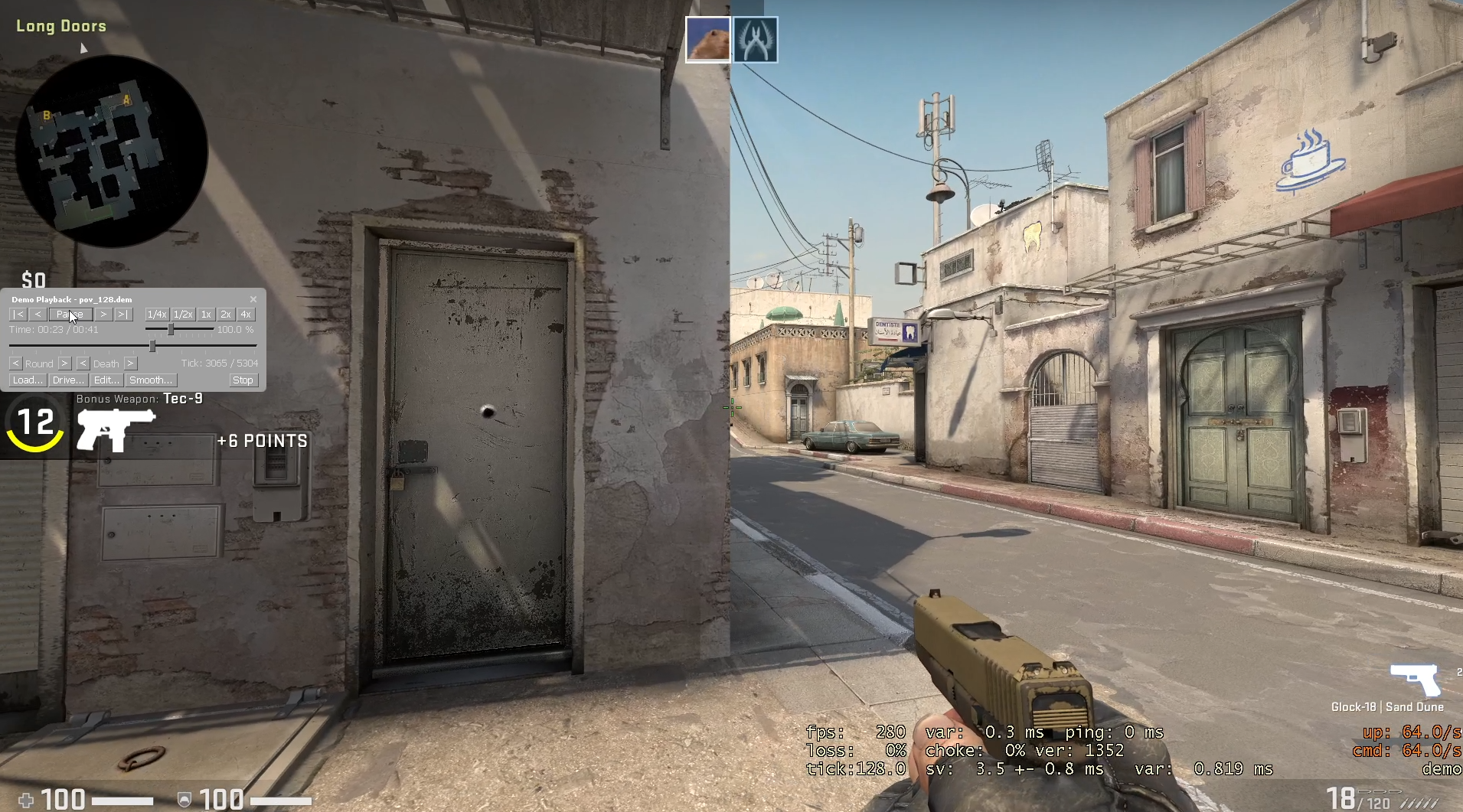
I found that both demos are inaccurate, but that POV demos are more inaccurate for a single example. The images on the right show a peek on a bot. The top most image is ground truth, a screen recording of the live gameplay. This image shows my crosshair under the middle window at the end of A long on the first frame when the bot becomes visible. On the first frame when the bot is visible for the GOTV demo, my crosshair is slightly to the right of the position from the screen capture (under the rightmost window at the end of A long). On the first frame when the bot is visible for the POV demo, my crosshair is left of the bot. The POV demo's crosshair position is far more inaccurate. This is not a tick issue, as the POV demo is at 64 tick and the GOTV demo is at 32 tick. I recorded the gameplay with net_fakelag 50 to introduce some mildly realistic network conditions. For more details, here are the videos from the screen capture, the GOTV demo, and the POV demo. Also, here are the GOTV demo and POV demo.
Request For Help
I want to accurately record visibility and reaction time from demos. If you have advice on how I can improve, please email me at durst@stanford.edu.