CSGO Players Use A Lot of Context Clues
My old anti-cheat model failed because it couldn't account for the context of real CSGO matches. The model identified cheaters by looking for players with implausibly fast reaction times' over three-round intervals. The intuition for this aggregate approach was: (1) cheaters consistently have fast reaction times because they know where enemies will appear before they become visible; (2) legit experts occasionally have fast reactions by pre-aiming (correctly guessing locations where enemies may appear), but these few correct guesses can be smoothed out.
The model attempted to account for pre-aiming by rating the challenge of a correct pre-aim and averaging over multiple pre-aim attempts. It's harder to guess a pre-aim location correctly when there are more options, so the model included a feature tracking the number of good pre-aim options given a player's current position. The model considered multiple pre-aim attempts by averaging reactions over a three round period.
The model's approach would've worked if CSGO is a sequence of independent guesses, like blackjack. Blackjack can be considered a sequence of independent hands; each time the player guesses the dealer's hand. My model assumed that CSGO is a sequence of independent guessing situations. A legit CSGO player in each situation has multiple pre-aim options, randomly guesses one of them without any context clues, and has a fast reaction if they guess right or a slow one if they guess wrong. The cheater with wallhacks will always have fast reactions because they will always guess correctly.
The below videos demonstrate this simplified view of CSGO. The player enters B tunnels on de_dust2. There is one enemy in the tunnels. The player needs to guess whether the enemy is on the left or right side. The player has no context clues from the game state about the enemy's position. This situation results in a 50/50 gamble (50% chance of being right, 50% chance of being wrong): guess correctly (look left) and win with a fast reaction or guess incorrectly (look right) and lose with a slow reaction.
Look Left, Win 50/50 Gamble
Look Right, Lose 50/50 Gamble
The below video demonstrates a cheater who always has fast reactions. Their wallhacks enable them to see enemies before they become visible, so they never guess wrong.
Cheater Always Looks Left
My anti-cheat model failed because CSGO isn't a sequence of independent guesses. CSGO has a lot of context clues. These clues enable legit players to pre-aim correctly and have fast reactions far more frequently than if they were guessing randomly. The video on the right demonstrates a legit player who uses context clues to make an informed guess and pre-aim correctly. At the start of the round, the player looks through CT spawn into CT mid. Also, his teammates cover A site. Finally, he knows the enemies' spawns prevent them from being in pit or side. He only has to check one angle at the end of the video: long doors. This results in a pre-aim at the enemy as they run around the wall.
Understanding CSGO Context Is The Important Challenge, Not Finding Cheaters
Understanding player behavior within that context is larger than just anti-cheat. If you understand how individual humans' respond to specific contexts, you can address a plethora of applications. Coaching is about identifying bad decisions in a specific game's context and recommending the right decision based on the context, gradually providing enough context-specific examples that the player learns an intuition for how to make good decisions generally. Similarly, forming a successful team requires understanding which individual decisions combine well in specific situations.
My new goal is to create a bot that "plays like" a human. This doesn't mean it has the same actions, like it presses the WASD keys for the same length and moves the crosshair mouse the exact same way. When I study a player's demo files, I don't analyze the keystrokes and per-frame crosshair movement. I think about higher level outcomes like where they traveled in the map, what pre-aim angles they looked at, and what parts of the enemy they hit during engagements. My goal is to create a bot that produces the same distribution of outcomes for a specific situation as a specific human. I can then use the imitation bot to compare human behaviors by comparing their outcome distributions.
As a reader, a few questions should pop in your head in response to the following paragraph:
- Can I Use A Simpler Approach? - Yes, there are simpler, discriminative approaches that merely evaluate play and predict some property of the play (like cheating) rather than generative approaches (like the bot) that produce an actual gameplay behavior. I could imagine a better anti-cheat discriminative approach that accounted for game context. However, I'm personally more excited about a generative approach. I want to play against imitation bots. I also think these generative bots could generalize to a broader range of discriminative tasks by comparing players (via their imitation bots' gameplay) rather than directly analyzing human's gameplay.
- What Is Your Method For Creating The Imitation Bot? - See below.
- How Will You Know If Your Bots Are Working? - See below.
Predicting Distributions Of Outcomes Merges AI and Statistics
The simplest approach for an imitation bot is memorizing all humans' actions in all situations. If the bots imitate players' actions correctly, then the same outcomes will occur. In an ideal world, I would record every combination of human players in every situation: for all 10 combinations of humans that play CSGO, I would get one data point for all possible combinations of players' (x,y,z) positions, (yaw, pitch) view angles, weapons, grenade counts, and armor/health values. During gameplay, the bots would then look up the current game state in this big dictionary of states and take the same action as the human took, like hold the W key or move the crosshair 10 degrees left.
The ideal world clearly doesn't exist because:
- State Space Too Large - The state space is too large. I can't record a data point for all situations and players. If you think of my imitation bot as a function from game state S and human H to an action A, Π(S, H) -> A, the function isn't defined for all states and humans.
- Humans Are Inconsistent - Even if I did have data to cover the entire state space for all humans, people are inconsistent. They aren't going to always hold the W key for the same length of time or move the mouse with the exact same way. If you think of my imitation bot as a function from game state and human to an action, Π(S, H) -> A, the function isn't actually a function because a function maps each input to at most one output. I have two (or more) different outputs for the same input: Π(S, H) -> A1 and Π(S, H) -> A2.
AI Researchers Know How To Handle Large State Spaces
AI researchers working in Imitation Learning know how handle large state spaces with incomplete data. Imitation learning trains bots to follow a policy function from state to action (the Π above) matching the recorded states and actions in a data set. Prior work includes learning DNNs to predict Π(S) -> A in soccer, basketball, and CSGO deathmatches. The DNN infers how to act in a new situation's context by interpolating between other contexts. I will take the same approach to deal with my state space. Also, I will try to expand upon their per-player customization. While the Soccer work has a section on per-team customization, most of this research tries to learn an average human policy rather than the policy of a specific human.
Baseball Statisticians Know How To Handle Inconsistency
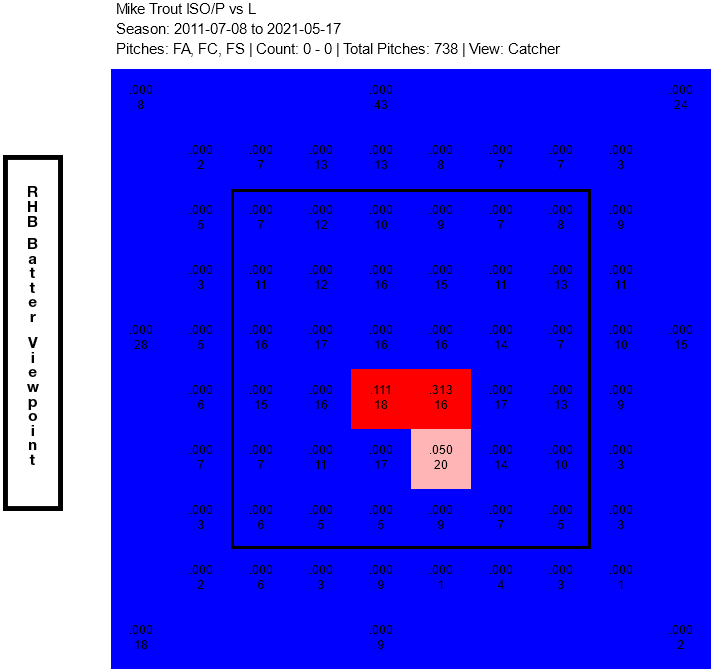
I can deal with inconsistency in results by focusing on distributions of outcomes rather than individual actions, like baseball's Sabermetrics. One reason statistical approaches like Sabermetrics are so successful in baseball is that the game can be broken down into smaller sub-games, each of which has only a few outcomes. For the sub-game of a batter hitting a pitch, one possible state space is the strike zone, discretized into a 10x10 grid; ball/strike count; pitch type; and the pitcher type. One possible distribution of outcomes is ISO (isolated power): probability of hitting a double, triple, or home run, weighted by number of bases. This state space and outcome distribution abstracts away all a lot of detail, but enables us to make predictions about players outcomes that can be interpreted by humans. In imitating Mike Trout, I don't care about how he strikes the ball (swing speed, swing angle), I just want to replicate how many extra base hits he has in a specific situation, as shown in the chart on the right. The chart shows his isolated power in 0-0 counts on fastballs from left-handed pitchers. Trout hits for power frequently on strikes in the lower-middle part of the plate and nowhere else. A bot imitating him should has the same distribution of outcomes.
Note for the computer science experts: I know that (a) distributions of actions is not a novel idea, as MDPs have long used probabilistic policies; and (b) existing deep learning RL models treat their model outputs as a distribution of move probabilities. However, these approaches are designed for considering multiple options when trying to win the game (aka maximize reward), not imitating an inconsistent and suboptimal human. For imitating an inconsistent human, I want to go a step further and incorporate the prior of inconsistency by designing the model to explicitly predict distributions and evaluating loss based on distribution similarity. I want my atom of comparison to be (state, outcome distribution) pairs, not (state, action) pairs.
CSGO Sub-Games


I will break CSGO into a hierarchy of four sub-games. For each sub-game, I will explain the goal, the input for a bot's model that imitates a player's behavior in the game, the output of the model, and how I will create training data for the model.
-
Long Term Path Planning - A player must choose their path through the
map. The CSGO developers have been kind enough to breakdown the maps into areas
via the nav mesh and merges together these areas in area groups with
semantically meaningful names. The goal of the sub-game is to choose a sequence of adjacent area
names that ends with one of two objective area groups (BombsiteA, BombsiteB).
- Model Input - The model's input will be the following game's state since the start of the round: deaths, own and teammates' prior and current paths, own and teammates weapons, own and teammate's money, own and teammates health, enemy spawns, time since spawn, last time/position enemy seen (or heard), enemy weapons (if enemy fired or enemy was seen), enemy weapons in prior rounds, enemy health < 10, enemy health < 50.
- Model Output - The model will output a distribution of area group trajectories. The trajectory ending points will depend on the player's team. For T's, they will end in one of the objective area groups. For CT's, they will end anywhere on the map.
- Training Data - I will convert human player positions into trajectories by recording sequences of map area groups. I will split trajectories within a single round based on (1) revisiting a map area group you already visited, (2) reaching an objective map area group if on T team. For computing the loss function, I will consider two paths equivalent if one terminates before the other, and they are equal up to the early termination.
-
Path Change - A player will choose to change their path in response
to new information. The goal of this sub-game is to choose when to change your path.
- Model Input - The model's input will be the same as above.
- Model Output - The model will output a distribution of a single boolean.
- Training Data - Every time a player leaves an area group, I will produce a new data point for the path changes data set. The point will be true if this is the last point in a trajectory (not resulting from death). It will be false otherwise. I will use the trajectory splitting criteria from above for creating these true/false labels.
-
Behavior In A Map Area - A player must choose their trajectory and
where to aim when moving through a single map area. Since this movement and aiming is relative to
other enemies and friends on a grid of map coordinates, I need to play this sub-game
on a grid rather than a graph of areas, like above. I will discretize the map by breaking down the
nav mesh areas into cells of 4x4 areas. 4 seems like a reasonable constant since it is 1/8 the
player width/depth of 32 and it makes the map de_dust2 (which is roughly 4000x4000) into a grid of
roughly 1000x1000 cells, similar in size to a downsampled image. (note: I want a small grid size so
I can capture subtle movements like shoulder peeking.) The goal of this sub-game is to determine the
immediate responses to your environment.
- Model Input - The model's input will expand upon the above models' inputs. First, I will include the current area group-level path. Second, I will ensure all positions also contain the cell number. Third, I will mark all cells as (a) not visible, (b) visible, (c) visible and in the player's viewport.
- Model Output - The model will output a distribution of cell trajectories; view angle trajectories; a (possibly null) target enemy index in a list of visible enemies to look at; boolean for if in an engagement; index for active weapon; and when and whether to crouch, jump, throw a grenade, or zoom.
- Training Data - I will produce a new data point every 150ms (roughly the fastest possible human reaction time) and every time a new enemy becomes visible. The target enemy will be the nearest enemy to a player's crosshair during the 150ms interval in terms of yaw and pitch after adjusting for recoil. Engagement is true if the player fires. Computing the rest of the output features is standard.
-
Engagements - This model will predict a player's method of and skill
at killing the enemy.
- Model Input - The model's input will be the same as for Behavior In A Map Area.
- Model Output - The distribution of engagement lengths in seconds, burst lengths, accuracy, boolean for headshot, angular acceleration, mouse velocity.
- Training Data - For each engagement in the Behavior In A Map Area training data, I will produce an engagement data point. Computing the values is standard.
At inference time, these models will produce outcome distributions. The actual mouse and keyboard actions will be determined by picking an outcome from the distributions and solving for actions that produce the outcome. The outcome for the keyboard inputs will be determined by the Behavior In A Map Area model. The outcome for the mouse inputs will be determined by the same model, unless the bot is currently in engagement. Then, the outcome for the mouse will be determined by the Engagements model.
Evaluation Is Based On Higher Level Outcome Analysis
I will evaluate my imitation bots based on distributions of summary statistics. For the soccer researchers, their key summary statistic was goals scored. They looked at distributions of that statistic by comparing its expected value from simulated games to the actual goals scored in human matches. For CSGO, I will use distributions of the standard statistics: win/loss ratios, K/D ratios, average damage per round, flashes thrown per game, enemies blinded in a flash. Rather than comparing expected values, I will assume that the summary statistics form a normal distribution and use a T-Test to determine if the summary statistics from actual human player matches are of the same distribution as summary statistics from imitation player matches.
If you have questions or comments about this analysis, please email me at durst@stanford.edu.