Learning Many Sub-Policies Is Hard
Last year, I built a hand-crafted behavior tree CSGO bot. I wanted the bot to imitate human behavior. The behavior tree provided an overall structure for human-like CSGO behavior, but the tree's sub-policies were lacking. They were hand-crafted to produce generally reasonable behavior. I wanted to learn them from human demonstrations so they could produce human-like behavior specialized to the current game state. While learning an entire bot from data is too challenging, I hypothesized that my approach would be easier because it would decompose the problem into many independently learned sub-policies. The sub-policies would be independently learned sub-problems in my overall process for bot design. The models for these independent sub-policies could be smaller and use custom features.
This hypothesis was wrong for two reasons:
-
The strict separation between learning and structure insufficiently reduced the difficulty of
learning each sub-policy. I need to use structure for more than just
- decreasing the scope of each learning problem
- feature engineering
- Decomposing one learning problem into many learning problems created too much engineering work. I needed to create feature engineering, visualization, and evaluation pipelines for each independently learned sub-policy.
My first learned sub-policy demonstrates these challenges. If my hypothesis was correct, then this learning problem should've been easy. However, I spent months training a mouse model that only sometimes aims at enemies like a human. The below video shows that the model looks good on simple examples where the enemy doesn't move. It moves to the target, overshoots, and corrects. However, it falls apart once the enemies start moving. Skip forward 20 seconds into the video to see these examples.
Let's dive into my difficulties training this mouse model.
Small Learning Problems Are Still Hard
My behavior tree's structure decreased the scope of the mouse model learning problem. This model doesn't handle movement or long-term planning. It doesn't handle mouse movement when the player lacks a clear target. The model only predicts a player's mouse movement and left mouse button state for the next tick (8ms) when engaging a target enemy based on the following data from the prior 100ms of game state:
- the player's state: their map position, velocity, weapons, health, crosshair angle, and recoil
- a single enemy target
- the target's position on the player's screen, and velocity in the world
My behavior tree's key simplifications are engagement definition and target selection. The tree defines when a player is selecting an enemy, so I only need to train on examples with a clear target. Second, the tree selects which target to aim at, if multiple are visible. Without the tree's structure, my model would've needed to solve both of these problems. Learning solutions to engagements and targeting is hard because it relies on the current visibility of the enemy and long-term memory of enemies' last visible positions. Visibility is a very complex analysis. My behavior tree has heuristics for visibility and memory, so it can handle all these problems in a non-learned way.
Prior work addressed all of these problems in one learned model, as well as others like navigation. Their model needed to solve a much more complex problem, so the mouse movement looks less realistic. (Or at least it looks less realistic for the subset of situations when both our models worked. I haven't done a complete analysis of both models' reliability.)
I used imitation learning techniques (Behavior Cloning with Data as Demonstrator and Scheduled Sampling) to train my model from pro recordings. My engagement definition was: 1 second before a player shoots an enemy to 200ms after their last consecutive hit. I ran some basic heuristics to ensure a player always had exactly one target. The below video shows the featurization of one engagement for my model.
Learning the mouse controller wasn't easy, despite my specialized features and limit scope. I had to contend with a classic machine learning issue: covariate shift. Covariate shift is when the distribution of inputs to a model during deployment doesn't match the distribution of inputs during training. This problem is particularly nasty in imitation learning because: (a) the model is trained from recordings of pros, who don't make the same types of mistakes as my model; and (b) the model's inhuman mistakes compound over time, causing worse and worse covariate shift. The model doesn't know what to do after a couple of mistakes and behaves in degenerate ways. For example, my model never sees a pro with terrible spray control, so it never learns how to recover from terrible spray control.
I spent a month or two implementing imitation learning techniques to account for covariate shift problem. These include Data as Demonstrator and Scheduled Sampling, which run the model in a simulator during training so it can experience it's own mistakes and learn how to recover from them. I even trained the model to predict its own recoil, so it could learn spray control in the simulator.
These techniques helped moderately but didn't solve the core problem: I have a uncontrolled DNN generating mouse movements. My only recourse to address covariate shift problems is more complex learning. The lack of control means that the smaller learning problem is still hard. There's no easy fix for forcing my model to behave correctly. Seemingly promising approaches, like overlaying a non-learned controller on top of the DNN, failed because the overlay didn't integrate well. Whenever there was a switch between the learned and non-learned controllers, the crosshair jumped around while the controllers adjusted to the change.
Each future, small learning problem will require solving similar (but not exactly the same) issues with covariate shift. Navigation will also have covariate shift issues, but for world coordinates rather than screen-space coordinates. To address these new problems, I'll need to reimplement similar imitation learning techniques in a new context. This is not a scalable process.
Each Small Learning Problem Requires a Lot of Engineering
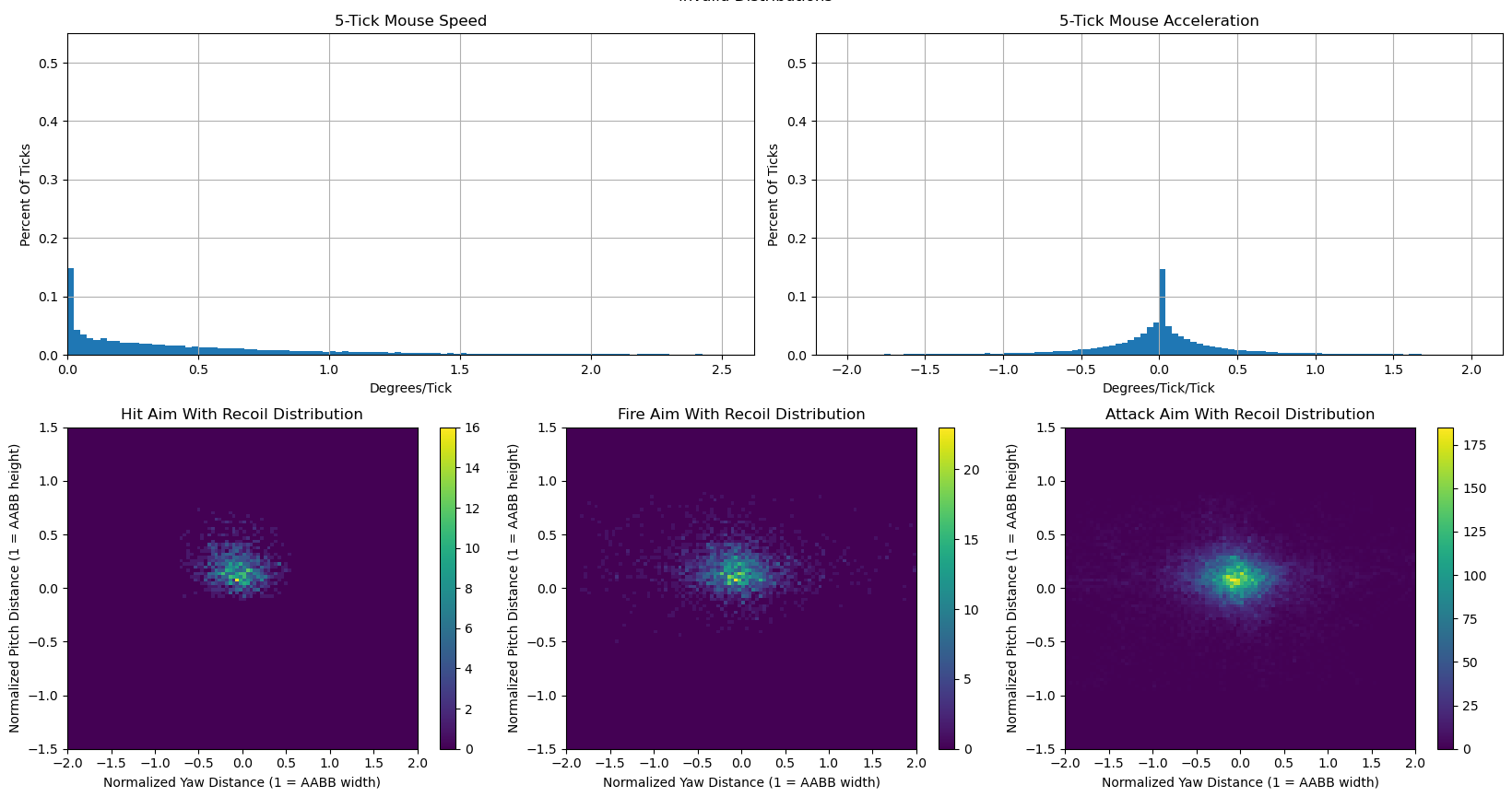
I had to spend a lot of time crafting the features for the model, the visualization system, and the techniques for evaluating success. You saw the features and the visualizations above. The below image demonstrates how I evaluate success. The graphs show the distributions of mouse speed, mouse acceleration, and position relative to the target when hitting them, firing, and holding the attack button. I compared these graphs for my mouse model and the human pros to demonstrate that my model was successfully imitating pros.
The charts below are from pro data. The top charts show that the pros frequently don't move their mice, but sometimes make large jumps. The bottom row shows that the pros aim at head level or above. This precision decreases on ticks in between shots fired. This is because the pros are adjusting for recoil in between shots, so they can be off-target before the next bullet comes out.
I would need to spend significant time building similar (but not exactly the same) pipelines for each other sub-policy. I would need new features, new visualizations, and new ways to evaluate distributions to show that my model imitated human behavior. I started creating features and visualizations for my navigation model. The below video shows the distribution of teammate positions and likely enemy positions over a round. A navigation model would use this to plot a course near teammates and with few angles exposed to enemies. I can't build many independent pipelines. It would take a year or two. And there's no guarantee that my independent models would work well. I'd still need to solve covariate shift for each one.
I'm Going To Learn One, Even Simpler Problem
The big takeaway from the last five months is: too many learning problems, and each one isn't easy enough. I'm gonna try to reduce my problem to one, even easier learning problem. My goal is just to learn parameters in my hand-crafted behavior tree. For example, my behavior tree has parameters for how long to remember no longer visible enemies and how fast to move the mouse when an enemy is visible. Hand-crafted controllers handle the job of interpreting those parameters and producing valid behaviors.
Since the parameters are interpeted within the context of my behavior tree, I have far more control. I can ensure that all possible parameter values produce valid behaviors. I don't have to overlay a hand-crafted model on-top of a learned one. Rather, I can ensure the parameters in the hand-crafted model can never be set to invalid values during learning. This means covariate shift will be less problematic. My model outputs are less likely to be catastrophically erroneous, so the model is less likely to experience inputs that weren't in it's training distribution.
The core problem with this approach is: how to design an efficient learning process for guiding these parameters. Modern ML works great because the opaque DNN's have a very efficient training process (backpropagation). It's much more challenging to train a few parameters stuck inside a bespoke model. This training difficulty seems like an acceptable trade-off in order to better combine learning and structure and solve my prior problems:
- reducing the number of learning problems
- limiting the learned policies' outputs to only valid values.
Request For Feedback
If you have questions or comments about this analysis, please email me at durst@stanford.edu.